Por Omar Gonzáles Díaz | June 16, 2019
¿Cómo obtener información de una web para su posterior procesamiento?
La habilidad de extraer data de un sitio web es invaluable para cualquiera que se quiera dedicar a hacer #datascience. En este post aprenderemos a extraer data con python y la librería BeautifulSoup.
Es también de mucha utilidad para fines educativos y puede ser de mucho provecho para fines comerciales. Por ejemplo, se podría extraer los productos, marcas, precios de diferentes ecommerce y elaborar un dashboard para comparar precios.
En este tutorial explicamos a grandes rasgos la lógica que se debe tener para extraer información de una página web. La cual se puede almacenar en una base de datos; y finalmente esta información podría mostrarse en un dashboard para tomar decisiones, etc.
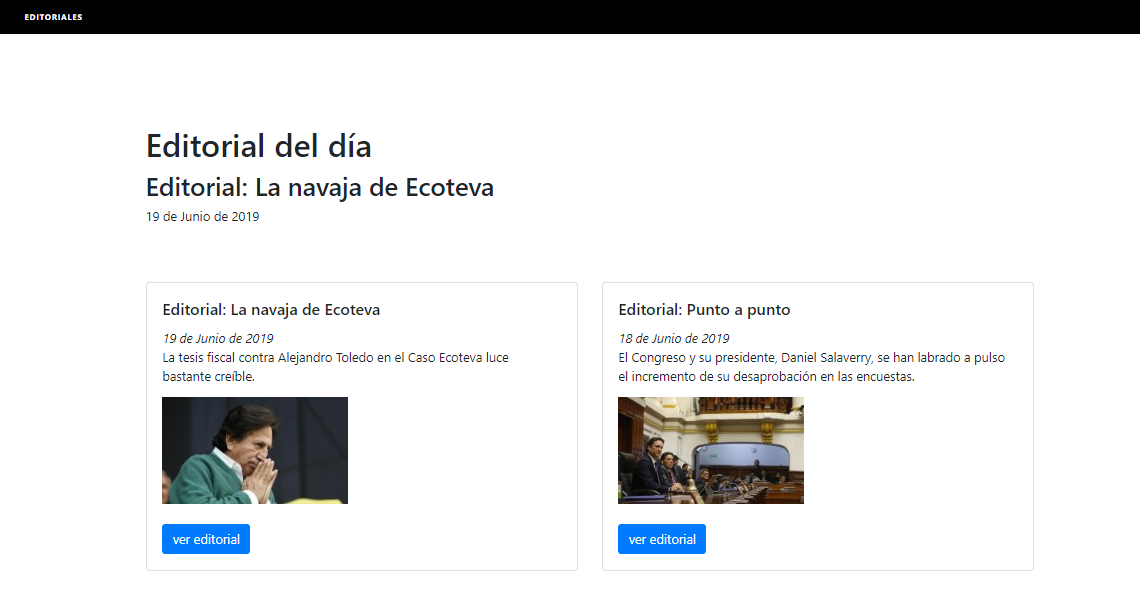
Esta es la app elaborada en django que finalmente se elaboró con la información que se extrajo utilizando este tutorial:
https://el-comercio-editoriales.herokuapp.com/
Esta webapp está programada para obtener la editorial del día a las 9 am y a las 12 pm.
En otros tutoriales les enseñaré cómo crear esta app en Django y subirla a Heroku. También cómo hacer gráficos con la librería D3, una de las librerías gráficas más potentes. Librería utilizada por medios como The Washington Post para elaborar gráficos dinámicos, entre otros.
Para este tutorial usaremos Python, aunque se podrían conseguir los mismos resultados con cualquier otro lenguaje de programación.
Las librería clave para extraer información utilizaremos es BeautifulSoup.
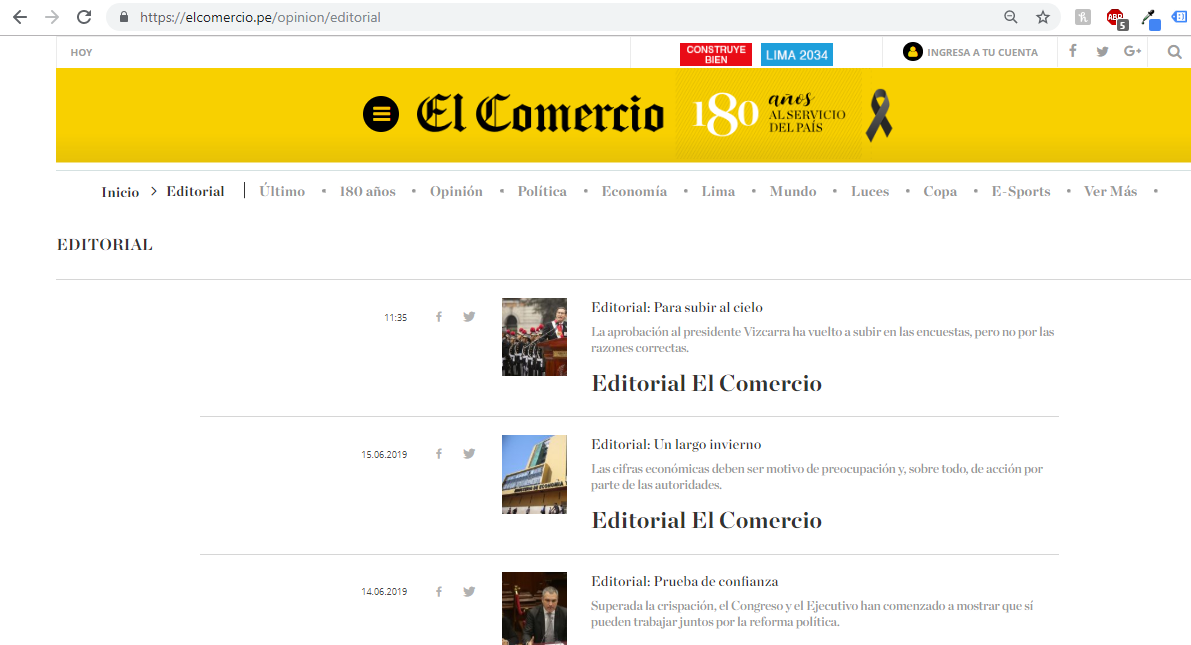
Y vamos a acceder a la sección de Editoriales de El Comercio, uno de los más respetados diarios nacionales de Perú.
Esta es la URL de esa sección: https://elcomercio.pe/opinion/editorial
Básicamente las primeras líneas del código que mostraremos al final del post lo que hacen es una solicitud a los servidores de la página web, que es lo mismo que hacemos cada vez que ingresamos la url de una página en algún navegador como Google Chrome.
Luego al llamar la función soup = BeautifulSoup(ec_editorial_scr) obtenemos la data estructurada, sobre la cual podemos navegar conociendo en qué partes del html de la página estamos interesados.
#Conocer la estructura de la web
Antes de poder extraer cualquier información de una página web es necesario conocer la estructura de la misma. Solo así podrás conocer dentro de que etiqueta HTML se encuentra la información que necesitas.
En el caso de las editoriales de El Comercio, cada editorial se encarma dentro de etiquetas <article>, a continuación les mostramos la estrcutura completa:
<article>
<div class="flow-detail">
<h2 class="flow-title">
<a class="page-link" href="/opinion/editorial/editorial-navaja-ecoteva-noticia-646742">Editorial: La navaja de Ecoteva</a>
</h2>
<p>La tesis fiscal contra Alejandro Toledo en el Caso Ecoteva luce bastante creíble.
</p>
</div>
<figure class="flow-image">
<a>
<picture>
<source data-type="srcset" srcset="https://img.elcomercio.pe/files/listing_ec_seccion_ultimas_noticias_deporte_total/uploads/2019/06/18/5d0986a099e79.jpeg" data-srcset="https://img.elcomercio.pe/files/listing_ec_seccion_ultimas_noticias_deporte_total/uploads/2019/06/18/5d0986a099e79.jpeg" media="(max-width: 610px)" class="" id="" style="">
<img data-type="src" class="" src="https://img.elcomercio.pe/files/listing_ec_seccion_ultimas_noticias_deporte_total/uploads/2019/06/18/5d0986a099e79.jpeg" data-src="https://img.elcomercio.pe/files/listing_ec_seccion_ultimas_noticias_deporte_total/uploads/2019/06/18/5d0986a099e79.jpeg" alt="" id="" style="">
</picture>
</a>
</figure>
</article>
En nuestro caso, la información de las editoriales que necesitamos se encuentran en etiquetas <article>, pero dentro de esta etiqueta hay otras etiquetas html que contienen la información que necesitamos. Y estas son:
Por ejemplo, para obtener:
Titulo de la editorial: <h2> con la clase flow-title, y dentro de esta etiqueta <h2>, encontrar la etiqueta <a> con la clase page-link.
Subtitulo de la editorial: para el caso del subtítulo, que en código verán le hemos llamado texto, debemos encontrar la etiqueta <p> con la clase flow-summary.
La imagen de la editorial: para el caso de la imagen del editorial hemos de buscar la etiqueta <source> y obtener el valor del atributo ["data-srcset"].
Código Python para extraer la editorial del día
En la página de editoriales de El Comercio lo que encontramos es una lista de las últimas editoriales. A nosotros nos interesa la editorial del día, así que con el siguiente código vamos a obtener la última editorial publicada.
Cada línea tiene un comentario que explica que hace el código, sin embargo, no dudes en dejar un comentario si tienes alguna duda sobre el mismo.
import time
from time import mktime
from datetime import datetime
import requests
from bs4 import BeautifulSoup
from time import mktime
ec_editorial = requests.get("https://elcomercio.pe/opinion/editorial") #solicita contenido de la página al servidor de EC.
ec_editorial_scr = ec_editorial.content #accedemos al contenido devuelto por la solicitud hecha.
soup = BeautifulSoup(ec_editorial_scr) #obtenemos la data estructurada, el html y sus etiquetas
enlace = soup.find('a', class_='page-link') #extrae el enlace
titulo = soup.find('h2', class_='flow-title').find('a', class_='page-link').getText().strip() #extrae el títutlo
texto = soup.find('p', class_='flow-summary').getText().strip() #extra el subtítulo
imagen = soup.find('source')["data-srcset"] #obtiene enlace de la imagen usada en la editorial
full_url = "https://elcomercio.pe" + enlace['href'] #obenemos la url completa para leer la editorial completa en el portal de El Comercio
Gracias por leer este post.
Me puedes contactar a oma.gonzales@gmail.com.